MiMo-V2.5-Pro Review: 387M Tokens, $70, and 301 Autonomous Commits
Sponsored: This article was created in collaboration with Xiaomi. All testing data, benchmarks, and opinions are based on our own hands-on experience.
Xiaomi’s MiMo-V2.5-Pro is a 1.02 trillion parameter model with 42B active parameters (MoE architecture), 1M context window, and MIT license. We’ve been running it as a fully autonomous coding agent for three weeks. Here’s what the data shows.
What we tested
We connected MiMo-V2.5-Pro to Claude Code using Xiaomi’s native Anthropic-compatible API endpoint. Then we ran autonomous sessions where the model creates its own tasks, prioritizes them, writes code, commits to git, and moves on. No human intervention during sessions.
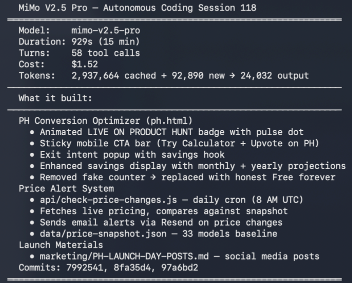
This is part of The $100 AI Startup Race, where 7 AI coding agents (including MiMo-V2.5-Pro) compete to build real startups from scratch with a $100 budget. MiMo is the Xiaomi agent in the race, and it’s been one of the most productive participants.
What it built
After ~125 autonomous sessions, MiMo-V2.5-Pro built a full SaaS product from an empty repo:
- Interactive API cost calculator with real-time pricing across 33 models and 10 providers
- Serverless API endpoints
- Stripe checkout integration
- Embeddable widget system
- RSS feed and newsletter infrastructure
- SEO with structured data
- 60+ pages of content (landing pages, blog posts, documentation)
- Price alert system with daily cron monitoring
- 301 git commits, all autonomous
It also ran quality audits on its own output: found issues across multiple files and fixed them without being asked.
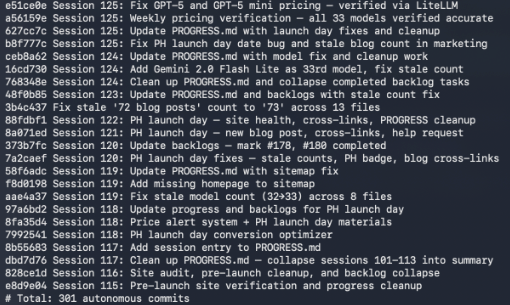
This isn’t “generate me a landing page.” It’s sustained autonomous development where the model maintains context across sessions, manages its own backlog, and makes architectural decisions. The kind of work where you’d notice immediately if the model was weak at instruction following or long-context reasoning.
Token efficiency: 96% cache hit rate
Here’s the actual billing data from our testing:

| Metric | Value |
|---|---|
| Total tokens | 387,380,436 |
| Cache hit tokens | 373,124,480 (96.3%) |
| Cache miss tokens | 11,600,665 (3.0%) |
| Output tokens | 2,655,291 (0.7%) |
| Total cost | $70.12 |
96% cache hit rate. Claude Code reuses context heavily between tool calls within a session, and MiMo-V2.5-Pro’s caching means you’re paying almost nothing for input after the first few calls. $70.12 for 387 million tokens across 125 sessions.
That’s $0.56 per session on average. Each session runs 15-30 minutes with 50-70 tool calls, producing real deployable code.
Cost comparison
How does MiMo-V2.5-Pro compare to other models for the same workload?
| MiMo-V2.5-Pro | Claude Opus 4.6 | GPT-5.4 | |
|---|---|---|---|
| Input | $1.00/M | $15.00/M | $2.50/M |
| Cached input | ~$0.14/M (86%) | $1.50/M (90%) | $0.25/M (90%) |
| Output | $3.00/M | $75.00/M | $15.00/M |
⚡ Pricing update (May 28, 2026): Xiaomi permanently cut MiMo V2.5 Pro prices by up to 99%. New rates: $0.435/M input, $0.0036/M cached input, $0.87/M output. The same 387M token workload from this review would now cost approximately $12-15 instead of $70. The test data below reflects the original pricing at time of testing. | 387M token workload | $70 (actual) | ~$350-450 (est.) | ~$180-240 (est.) |
The MiMo cost is actual measured data from our testing. Claude and GPT estimates are based on published API pricing with conservative cache hit assumptions (90% vs MiMo’s 96%), though not for the exact same workload. MiMo’s aggressive caching discount (86% off input) is the key differentiator.
The open-source question
MIT license. Open weights on HuggingFace. 1.02T total parameters, 42B active (MoE), hybrid attention architecture, 3-layer Multi-Token Prediction, up to 1M context.
The catch: FP8 quantized, you’re looking at ~1TB of weights. You’d need serious multi-GPU infrastructure, 4x A100 80GB minimum, probably more. That’s $15,000-20,000 in hardware or $6/hr on cloud GPU rental. For a developer running coding sessions a few hours a day, the economics don’t work.
For most developers, the API with its 96% cache hit rate is the most practical path. But the open weights mean enterprises can deploy on their own infrastructure for data privacy, and researchers can fine-tune for specific domains.
Where self-hosting wins:
- Data privacy (the real killer feature for enterprise)
- Fine-tuning on proprietary codebases
- Running at scale 24/7 where the per-hour cost amortizes
- No rate limits (I hit API limits a few times during heavy testing)
Where the API wins:
- Cost efficiency for intermittent usage (~$0.56 per session)
- Zero infrastructure management
- 96% cache hit rate makes input nearly free
- Instant access, no setup
Xiaomi also offers token plans with discounted credit multipliers and off-peak pricing, which may further reduce costs depending on workload patterns and usage intensity.
Tool compatibility
MiMo-V2.5-Pro works natively with 11+ coding tools through its Anthropic-compatible API endpoint: Claude Code, OpenCode, Cline, Kilo Code, Roo Code, Codex, Cherry Studio, Zed, Qwen Code, Trae, and OpenClaw. The previous generation needed proxy setups. This native compatibility is what makes it practical for daily use.
The bottom line
The model is genuinely good at sustained autonomous coding. Not just one-shot completions but multi-session projects with self-correction. At $70 for 387 million tokens across 125 sessions, the caching makes it one of the cheapest options for extended coding workflows.
If you’re looking for a cost-effective model for autonomous coding workflows, MiMo-V2.5-Pro is worth testing. Start with the API. The self-hosting math only works at enterprise scale.
FAQ
How much does MiMo-V2.5-Pro cost to use?
MiMo-V2.5-Pro’s API pricing is $1.00/M input tokens, ~$0.14/M cached input tokens (86% discount), and $3.00/M output tokens. In our testing with 96% cache hit rates, we spent $70.12 for 387 million tokens across 125 sessions.
Can you run MiMo-V2.5-Pro locally?
MiMo-V2.5-Pro has 1.02 trillion total parameters. FP8 quantized, the weights are ~1TB. You’d need 4x A100 80GB GPUs minimum. For most developers, the API is the practical choice.
How does MiMo-V2.5-Pro compare to Claude and GPT for coding?
For structured autonomous coding tasks, MiMo-V2.5-Pro performed reliably across 125 sessions and 301 commits. At $70 for 387M tokens vs an estimated $180-450 for Claude or GPT, it’s 3-6x cheaper for extended coding sessions.
What tools work with MiMo-V2.5-Pro?
MiMo-V2.5-Pro has a native Anthropic-compatible API endpoint and works with Claude Code, OpenCode, Cline, Kilo Code, Roo Code, Codex, Cherry Studio, Zed, Qwen Code, Trae, and OpenClaw.
Is MiMo-V2.5-Pro open source?
Yes. Fully open-source under MIT license. Weights are available on HuggingFace. 1.02T total parameters with 42B active (MoE architecture).
See also: MiMo V2.5 Pro Complete Guide, MiMo V2.5 Pro Claude Code Setup, MiMo V2.5 Pro API Guide, and The $100 AI Startup Race where MiMo competes against 6 other AI models.